Example
A general framework for growing a decision tree is as described below. Start with a tree with a single leaf (the root) and assign this leaf a label according to a majority vote among all labels over the training set. Now perform a series of iterations. On each iteration, we examine the effect of splitting a single leaf. Now define some "gain" measure that quantifies the improvement of information, or in other words reduction of entropy due to this split. Then, among all possible splits, either choose the one that maximizes the gain and performs it, or choose not to split the leaf at all. In the following, we provide a possible implementation. It is based on a popular decision tree algorithm known as "ID3" (short for "Iterative Dichotomizer 3"). The algorithm works by recursive calls, with the initial call being ID3 and returns a decision tree.
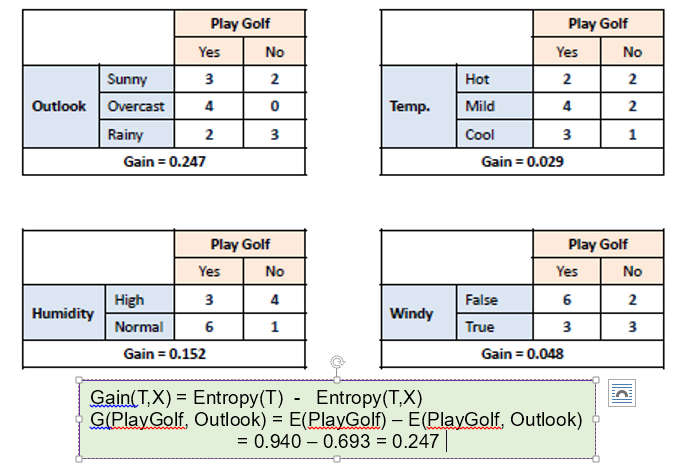
Let’s consider the following example of whether golf will be played or not respective with weather conditions
• Constructing a decision tree is all about finding an attribute that returns the highest information gain
• We want the most homogeneous branches

To build a decision tree, we need to calculate two types of entropy using frequency tables as
follows:
a) Entropy using the frequency table of one attribute:

b) Entropy using the frequency table of two attributes: in the following table we will consider
all three conditions for the output yes r no. count all 'yes' and 'No ' for sunny, overcast, rainy
and put in tabular form as shown below

(i.e., the most homogeneous branches).
|






No comments:
Post a Comment